


Demystifying LLMs Part 1
Neural Network Architecture

Neural Networks Primer: Understanding the Basics
Machine learning encompasses a variety of models, each designed to handle different types of data and tasks. Neural networks, one of the most influential models, were created to mimic the human brain's ability to learn from and make sense of complex patterns. Unlike traditional machine learning models that rely on predefined rules or simple statistical relationships, neural networks can automatically discover intricate patterns and relationships in vast amounts of data. This unique capability makes them especially powerful for tasks like image recognition, speech processing, and natural language understanding and generation.
Owing to these foundational strengths, neural networks were chosen as the bedrock of Large Language Models(LLMs), offering a robust computational framework to process and learn from vast amounts of data. LLMs are based on a more advanced form of neural network architecture called the transformer architecture, which was introduced in 2017 in a Google paper titled “Attention is All You Need.” To understand them, we will first break down the essential components of neural networks in this first post, presenting them in a way that's accessible to everyone.
Neurons: The Building Blocks
Neurons are the fundamental units of a neural network, inspired by the neurons in the human brain. Each neuron receives inputs, processes them, and produces an output. In a neural network, inputs are typically numbers, and the processing involves mathematical operations.
Imagine a neuron as a small decision-making unit. It takes in information, does some calculations, and then decides whether to "fire" (activate) or not, passing its output to the next layer of neurons.

Layers: Structuring the Network
Neurons are organized into layers. A neural network typically consists of three types of layers:
Input Layer: This is where the data enters the network. Each neuron in this layer represents a feature of the input data.
Hidden Layers: These layers perform computations and extract patterns from the data. A network can have one or many hidden layers, each adding more complexity and capacity to the model.
Output Layer: This layer produces the final result of the network's computations. The number of neurons in this layer depends on the task, such as classification or regression.

The number of layers in a neural network is typically determined through experimentation and trial and error. The optimal number of layers and neurons is highly dependent on the specific problem and dataset, and it is generally determined through extensive experimentation and evaluation, guided by domain knowledge and experience. For example Llama3 with 8B parameters have 32 layers.
Weights and Biases: The Tunable Knobs
Weights and biases are the parameters that a neural network learns during training. They determine how strongly each input influences the neuron's output.
Weights: These are the coefficients applied to the inputs. They represent the strength of the connection between neurons. In a mathematical sense, weights adjust the importance of each input. Think of weights as the parameters that the neural network adjusts during the training process to understand the relationships between inputs and outputs.
Biases: These are additional constants added to the neuron's output. Biases allow the activation function to be shifted left or right, which can be crucial for the network's ability to learn complex patterns.
Together, weights and biases are the tunable knobs of a neural network. They determine how information flows through the network and how each neuron responds to inputs. By adjusting these parameters, neural networks can learn to model complex relationships in data and make predictions or classifications.
Activation Function: Adding Non-Linearity
The activation function decides whether a neuron should be activated or not based on the weighted sum of its inputs plus the bias. This function introduces non-linearity into the network, allowing it to learn more complex patterns.
Common activation functions include:
Sigmoid: Outputs a value between 0 and 1.
ReLU (Rectified Linear Unit): Outputs the input directly if it is positive; otherwise, it outputs zero.
Tanh: Outputs a value between -1 and 1.
Jargon Demystified:
Parameters: parameters encompass all the values the model learns during training. This includes weights, biases, and any other tunable factors. During the training process, parameters are the elements that are adjusted to minimize errors in the model's predictions. When you hear that Llama3 has 8B or 70B parameters, it means that the model has trained 8 billion or 70 billion weights and biases, respectively.
Features: features are the individual measurable properties or characteristics of the data being used to train the model. They are the inputs that the neural network uses to learn and make predictions. For example, in an image recognition task, the features could be the pixel values of the image. In a customer segmentation task, features might include age, income, and purchase history. LLMs, however, do not have traditional features like other neural networks.
Deep Learning: In the above diagram you see a neural network with 5 layers. There is a misnomer that deep learning is dependent on the number of layers but it is rather dependent on what each layer does. If the network identifies lower-level features first and then builds upon them to learn higher-level features gradually then it is called deep learning. This technique is also called hierarchical feature learning.
Example: Putting It All Together
Now for the fun part. Let's consider a simple example of a neural network designed to predict how many ice creams would an ice cream truck sell on a given day. Considering the ice cream sales are dependent on temperature, time of day, and day of the week.
We will create a neural network with three layers input, hidden, and output with 3,3, and 1 neuron respectively.

For this example, consider a simple linear regression equation for the sale of ice cream.
Here w are the weights and b is the bias. This is what a neural network trains to produce what should be the values of these weights and biases based on the historical training data given to it. During training, the network adjusts its weights and biases to minimize the error in its predictions using algorithms such as backpropagation and gradient descent.
Suppose this is the training data you have. The input data to the neural network would look like x_train = [[86,3,14],[77,1,12],[68,7,18],…] and y_train=[45,30,20,…]
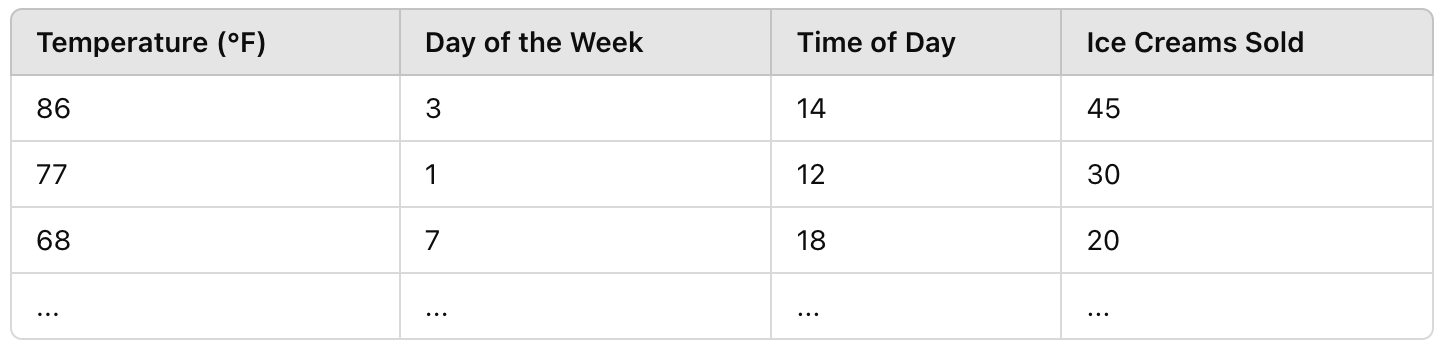
Now, let’s take a peek into what happens at different layers within the neural network. The neural network will initially select random values for the weights(w) and bias(b). These weights and biases are applied to the input features (temperature, day of the week, and time of day) through the above linear equation. Through multiple iterations, the network adjusts these weights and biases to minimize the prediction error for the number of ice creams sold. This iterative process is called training, where the weights and biases change until the network can accurately predict the output with minimal error. At every layer, the network is slowly understanding the patterns hidden in the data.
Once trained, the network can take any set of input values (such as temperature, day of the week, and time of day) and predict the number of ice creams sold with high accuracy. By learning the optimal weights and biases, the network becomes capable of generalizing from the training data to make reliable predictions on new data.
Conclusion
Understanding neural networks is crucial for grasping the fundamentals of large language models (LLMs), which are the backbone of modern AI applications. By delving into the roles of neurons, layers, weights, biases, activation functions, parameters, and features, we can comprehend how neural networks serve as the foundation for LLMs. These networks emulate the human brain to tackle complex problems, enabling LLMs to process and generate human-like text. Whether you're a tech enthusiast or a professional aiming to deepen your knowledge of AI, this primer provides a foundation for exploring the fascinating world of large language models and their underlying neural networks.